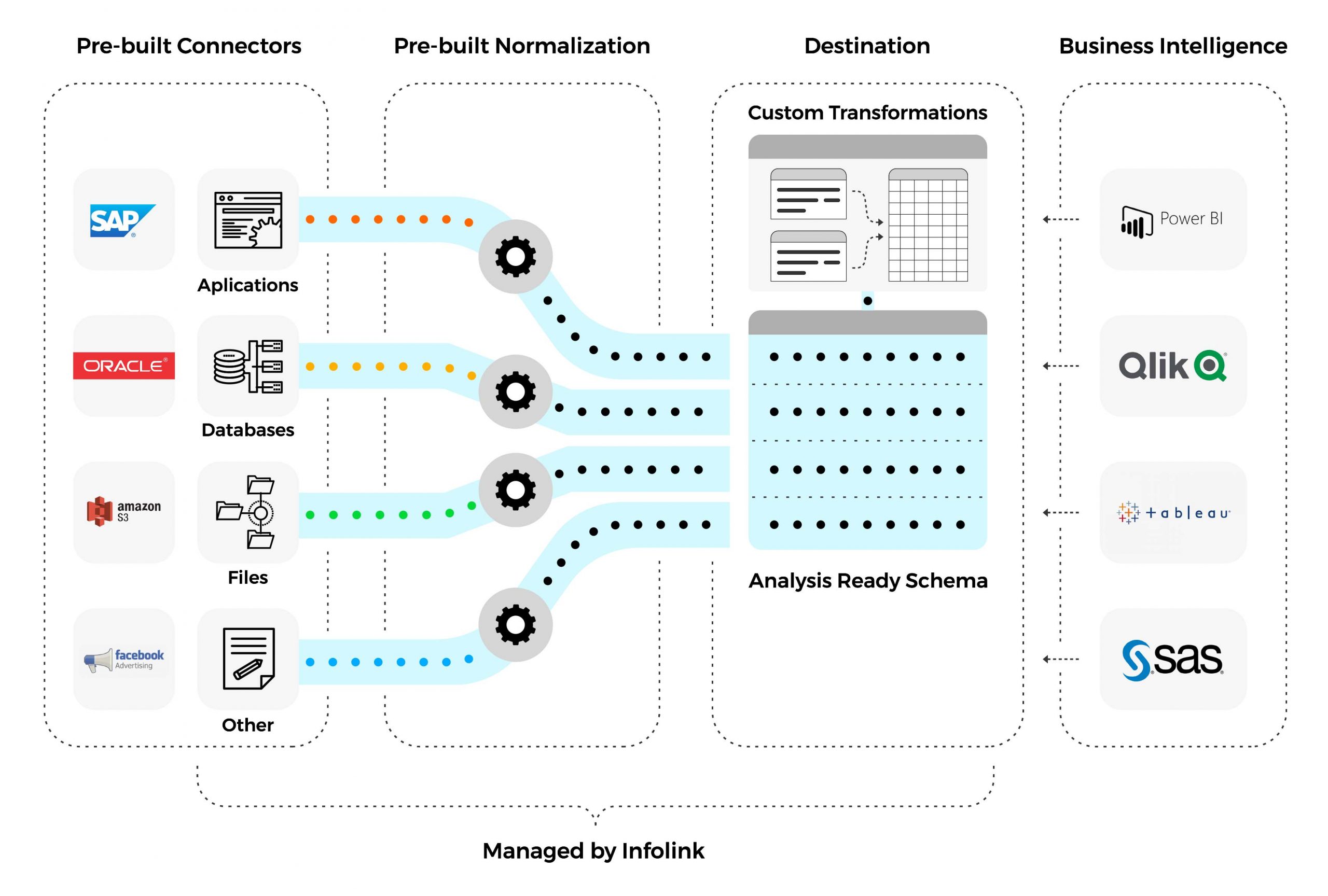
Data replication is the practice of creating a copy of data by tracking changes in the source. In contrast to bulk data loading, data replication minimizes the amount of data moved between the source and target and keeps data synchronized in real time. Data replication is used to make data available for analytics by copying from BI-unfriendly and legacy systems to modern platforms. Data replication is also used for disaster recovery and high availability of mission-critical data.